The most informative part of the detection function is close to the y axis, i.e. estimating the value of the detection probability density function on the transect line
This is why we prefer detection function shapes like half-normal, uniform and hazard-rate, because they have a good ‘shoulder’ where detection probability is high on the transect or close by
In contrast, your field data may contain a few observations very far from the transect. These distant animals:
Don’t contribute much useful information
Can make it more difficult to model the detection function
May have been detected by a different process1
Fitting detection functions
When you fit a detection function to your whole dataset, R may struggle to select curve parameters that fit the main dataset and the outliers
R will attempt to do this by adding more parameters to the detection function model, creating a detection function with a more complex shape
When you remove outliers, it’s easier for R to fit a simple detection function, so:
You calculate fewer detection parameters, meaning
You can include more covariates to predict density (which is what you’re really interested in!)
Right truncation
Right truncation is the step of removing distant observations
Truncation decreases the number of sightings you use, but this loss of (possibly misleading) information is outweighed by the reduced bias and increased precision of your detection function
Choose a truncation distance
There are three ways to decide which outliers to remove:
👀 Look for an obvious discontinuity (gap) in the data, beyond which observations are clear outliers
% Remove the most distant 5-10% of your observations
\(g(x)\) Removing all observations for which the detection probability has fallen to 15% or below
We recommend the last approach of truncating at \(g(x) \thickapprox 0.15\) as the most effective
In practice you might use a combination of approaches to give you confidence in your choice of truncation distance
Truncate at a discontinuity
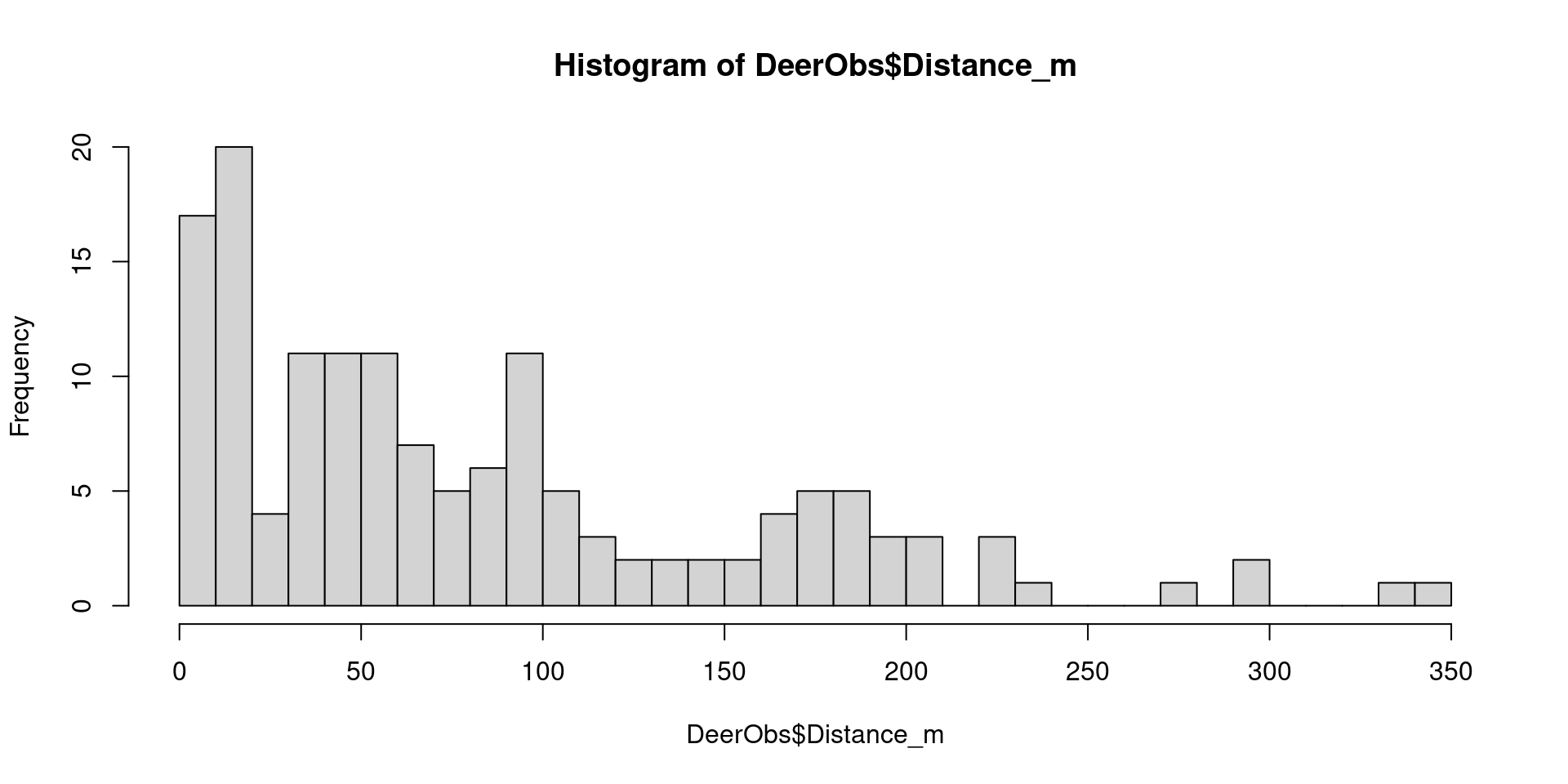
Plot a histogram of your sightings and examine it to identify gaps far from the transect:
Specify finer breaks to see detail (a similar plot to hist(distUMF))
What’s the first distance at which no water deer were sighted? Is there an obvious gap where it seems sensible to discard observations beyond that distance?
View raw observations
Another helpful way is to sum the distance bins from distUMF to see how sightings decline with distance from the transect
rescaled by estimated density on the transect line
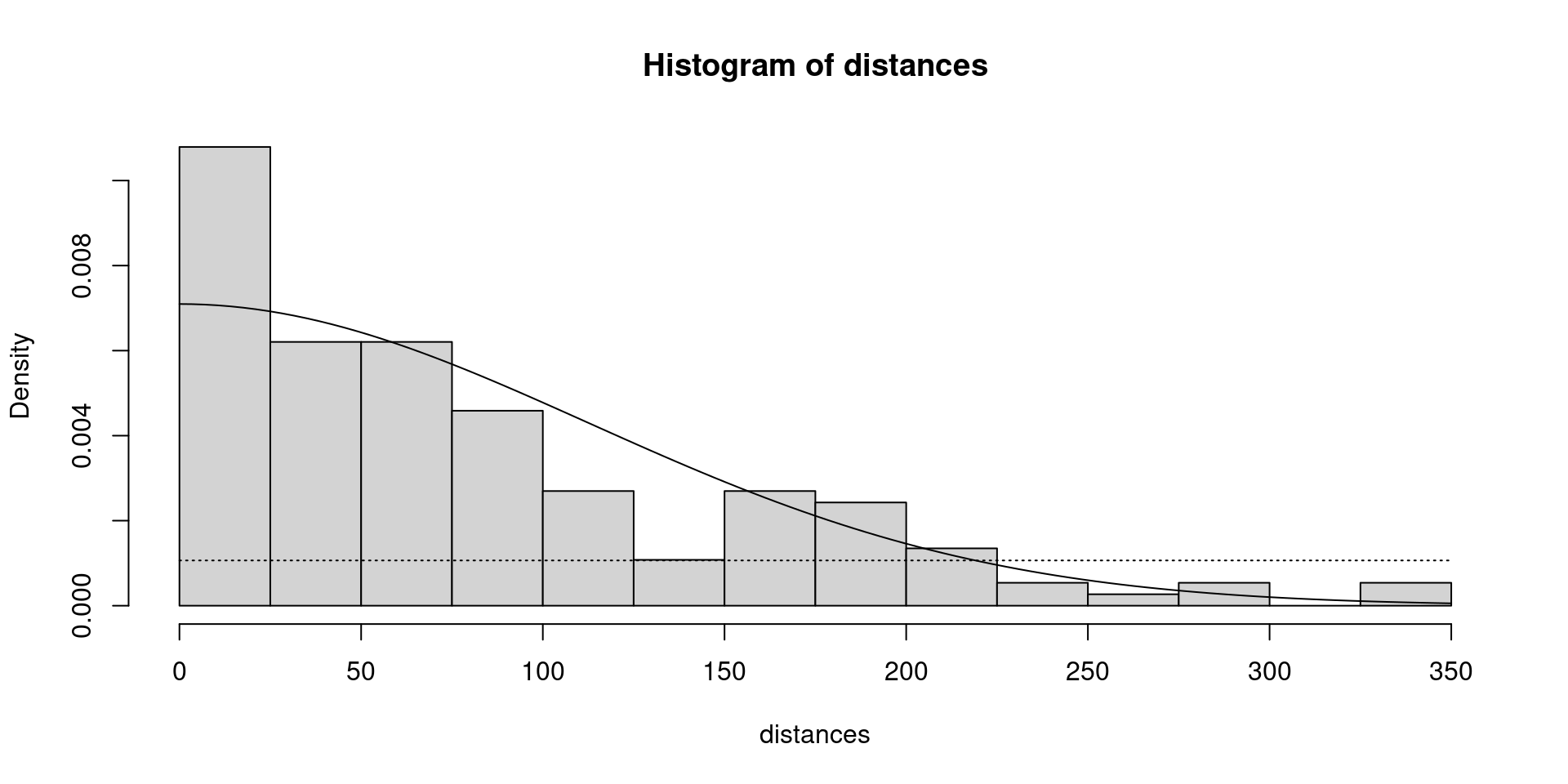
Your truncation distance is the point on the x axis (distance from transect) where the half-normal model curve and the dotted line \(g(x) = 0.15\) cross
Remember that the bars are every 25m, which helps you judge the x value where our lines cross
See the next slide for our plot
Where is detectability 15%?
Sightings with detectability < 15%
In this model, detectability is 15% around 220m from the transect line
For comparison with the truncation methods above, let’s find out how many of our sightings lie beyond 220m and would be discarded based on their detection probability being less than 15%
Using \(g(x) = 0.15\) is the most robust method for choosing a truncation distance
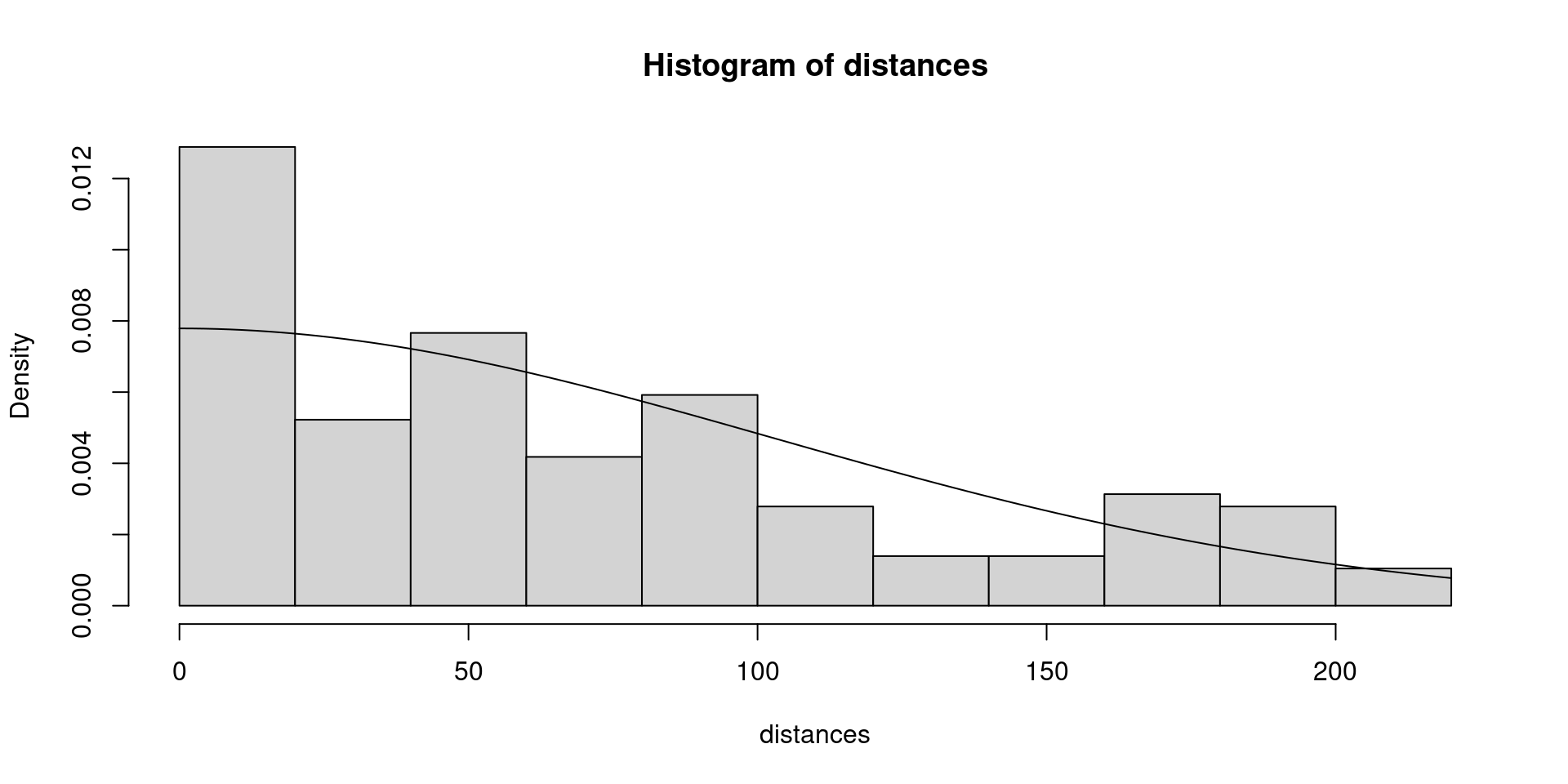
Run model on truncated data
Let’s truncate at 220m, as this lies in the middle of the distances suggested by visual discontinuities (250m) and removing 5% (222m) or 10% (190m) of observations
We need to:
Truncate the water deer dataset
Create a new UMF
Use the new UMF as input for a null model with a half-normal detection function
Create a new, truncated dataset:
DeerObsTrunc <- DeerObs[DeerObs$Distance_m <= TruncDist,] # Selecting obs within 220m
Create a new set of distance intervals, with a maximum of 220m:
TruncDistBins <-seq(0,TruncDist,20)
Create a truncated UMF
Format the subset of deer observations for conversion into a UMF:
unmarkedFrameDS Object
line-transect survey design
Distance class cutpoints (m): 0 20 40 60 80 100 120 140 160 180 200 220
12 sites
Maximum number of distance classes per site: 11
Mean number of distance classes per site: 11
Sites with at least one detection: 12
Tabulation of y observations:
0 1 2 3 4 5 6 7
68 29 17 7 5 3 1 2
Fit a model to truncated data
Fit the half-normal model to the truncated dataset and view the output: